Kubernetes Requests & Limits#
The Basics#
Requests#
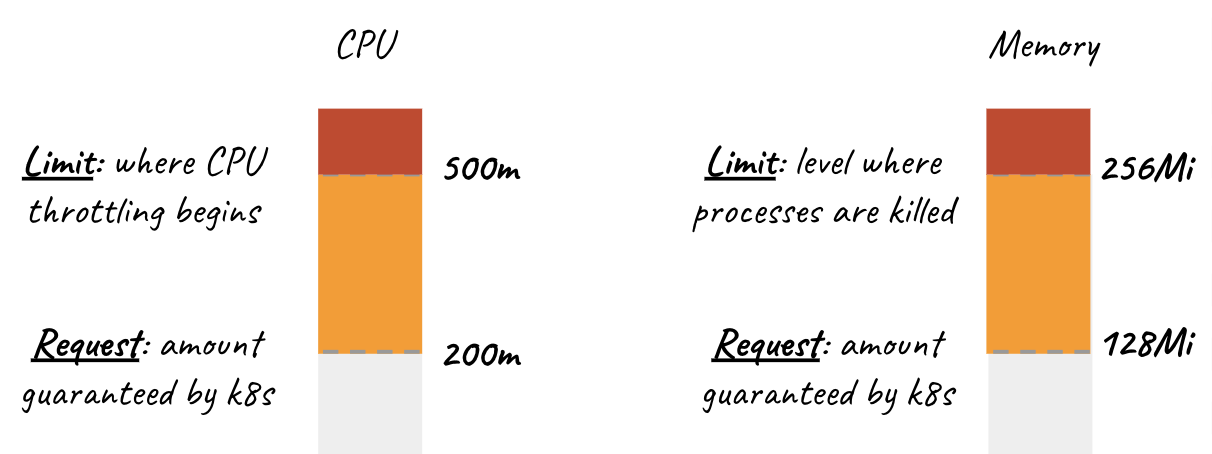
Pods will get the amount of memory/CPU they request. The requests specification is used at pod placement time: Kubernetes will look for a node that has both enough CPU and memory according to the requests configuration. If they exceed their memory request, they could be killed if another pod happens to need this memory. Pods are only ever killed when using less memory than requested if critical system or high priority workloads need the memory.
Limits#
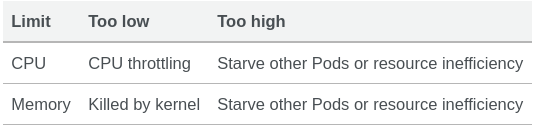
Limits are enforced at runtime. If a container exceeds the limits, Kubernetes will try to stop it. For CPU, it will simply curb the usage so a container typically can't exceed its limit capacity ; it won't be killed, just won't be able to use more CPU. Pods will be CPU throttled when they exceed their CPU limit. If no limit is set, then the pods can use excess memory and CPU when available. If a container exceeds its memory limits, it would be terminated.
Compressible Resources#
CPU is considered a “compressible” resource while memory is “non-compressible”.
Compressible means we can squeeze more out of it. Pods can work with less of the resource although they would like to use more of it. For example, if you deploy a pod with a request of 1 CPU and no limit, it can use more than that if available. But when other pods on the same node get busy, they will have to share the available CPUs and might get throttled back to their request. However, they won’t be evicted and can still do their job.
For memory on the other hand, when a pod has a resource request for memory but no limit, it also might use more RAM than requested. However, when resources get low, it can’t be throttled back to use only the requested amount of memory and free up the rest. There is a possibility that Kubernetes will evict such pods. Therefore it is crucial to always set a memory resource limit and take care that your microservice will never exceed that limit.
Similarly, even if you set limits CPU & memory on a pod, and pod reaches the limit CPU, the container will not get killed, rather it will be CPU throttled causing slowness. But if it reaches the memory limit, kubelet will kill the container stating OOMKilled(Out of memory killed)
Requests is a guarantee, Limits is an obligation#
There is a subtle change of semantics when we go from requests to limits. For the application developer, requests is a guarantee offered by Kubernetes that any pod scheduled will have at least the minimum amount of memory. limits is an obligation to stay under the maximum amount of memory, which will be enforced by the kernel.
In other words: containers can’t rely on being able to grow from their initial requests capacity to the maximum allowance set in limits.
Quality of Service#
QoS value for a pod determines how good the service of that pod will be. QoS can have three values
1. BestEffort#
The QoS when you set no Requests & Limits on your pods.
When you declare no resources, Kubernetes has no idea where to put the pod. Some nodes are very busy, some nodes are very quiet, but since you’ve not told your cluster how much room your deployment needs, it is forced to guess.
It won’t just starve your other pods, it can also going to escalate and consume the CPU that would otherwise be allocated for really important things, like the kubelet. Your node can go dark and on some platforms, it can be more than 15 minutes before your cluster self-heals.
2. Burstable#
The QoS when you set Limits is higher than Requests on your pods.
Better than BestEffort but if all of your pods have limits higher than your requests, and all/some of them grow simultaneously, they are over-committing the CPU/Memory from the node. The issue is again all the pods are using more memory and can again commit more memory & CPU from the node, resulting in node failure or OOMKill of your containers. If the upper bound of all of your pods is several times higher than the capacity of the node on which they’re running, you’ve potentially got a problem.
3. Guaranteed#
The QoS when you set Limits are equal to Requests on your pods.
It is the most expensive way to run your containers, but those containers gain an awful lot of stability. Each pod will schedule on a node that has enough resources and will never throttle the node but if it can be expensive as you would have to set a higher number for requests & limits.
Conclusion#
This is a bit of a value judgment. Some pods sit idle for a long time and, perhaps for an hour, they get busy. It doesn’t make sense to hold onto resources for the other 23 hours as Guaranteed QoS does. So you make the choice. Risk vs. reward. If the pod self-heals quickly and you can tolerate short outages, Burstable might be a good method for you to save some money.
The Tradeoffs#
Requests#

Limits#
Determining the right values#
There is no single right or wrong value, you need to calculate this based on your team's or microservice's usage and need. And this should be monitored explicitly for a period of time by the developers, to come to a final conclusion. For this, there are 2 options:
-
Either you can do this manually through Grafana & Prometheus and look for container CPU and memory usage and then update Request and Limit manually.
-
Use Vertical Pod Autoscaler
Solution#
Don't over-commit memory#
- Implement mutating admission webhook
- Set Requests = Limits
Default Namespace Configuration#
At the Namespace level, you can set up ResourceQuotas and LimitRanges. ResourceQuotas are maxed limits for all pods in a namespace while LimitRanges are for individual pods in that resources. If a pod does not explicitly define a specific resource, they will inherit the assigned values. For example, If no default value is assigned, it will inherit the default limits.
Development Tier#
Production Tier#
References#
CPU limit directly affects startup times.